When we think about the requirements of the real time data processing and storage for the use cases such as order processing, stocks, connected car etc. we might have to be very careful in taking such decision not only from the capability perspective but costing perspective as well. Below is a sample design for a design for a high end real time data processing with data ingestion, ETL/ELT with available open source technologies. External data ingestion and pre-processing techniques which needs to perform following actions:
- Real time stream processing with various tools.
- Data pre-processing and filtering out the raw data to business level data.
- Storage in Bronze, Silver and Gold storage.
Below is the sample design with available tools and techniques:
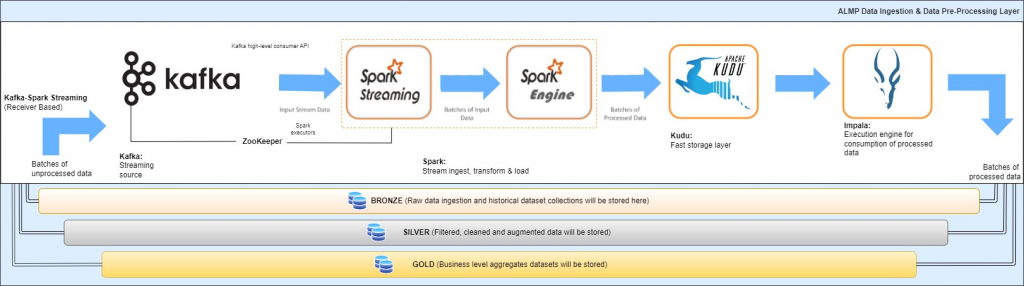
Data Ingestion & Data Pre-Processing Pipeline
The data pipeline design will be responsible for data processing and mapping various datasets for platform which is explained earlier to this.
Batch of Unprocessed Data
The raw data received from the external sources will be ingested to the data pipeline for further processing and mapping.
Batches of Processed Data
Once the real time data received in high volume and processed via the data pipeline this will be output as the batches of processed data and further will be stored to respective databases.
Batches of Processed Data
Once the real time data received in high volume and processed via the data pipeline this will be output as the batches of processed data and further will be stored to respective databases (Bronze, Silver and Gold)
BRONZE – Database
The database will be responsible to store the raw data ingestion and historical dataset collections. This may include critical information which needs to be further processed for anonymization, masking and other data security metrices as per the data privacy policy decided by the government.
SILVER – Database
The database will be responsible for storing the filtered, cleaned and augmented datasets which was received from the external partners to further process the data for the platform.
GOLD – Database
The database will be responsible most useful business level aggregates datasets to further utilized by the platform for various layers.
The design is based on open source available tools like Apache Kafka, Apache Spark Streaming, Apache Kudu and Apache Impala.